رایانشکده *** Computation Hub
محاسبات ریاضی، حل مسئله های برنامه نویسی و پیاده سازی الگوریتمرایانشکده *** Computation Hub
محاسبات ریاضی، حل مسئله های برنامه نویسی و پیاده سازی الگوریتمدرباره من
 Yours truly has graduated in Computational Linguistics from Sharif University of Technology and English Language and Literature from Shahid Beheshti University. I'm active in international business, computer programming and language teaching
ادامه...
Yours truly has graduated in Computational Linguistics from Sharif University of Technology and English Language and Literature from Shahid Beheshti University. I'm active in international business, computer programming and language teaching
ادامه...
جایگزین ارزیابی دوزبانه

روش «جایگزین ارزیابی دوزبانه»: ابزاری معتبر برای سنجش دقت در ترجمهی ماشینی
نویسنده: محمد رجبپور
در سالهای اخیر مهندسان کامپیوتر توانستهاند با پردازش دادههای انبوه زبانی به خصوص پیکرههای موازی بزرگ و بهکارگیری روشهای آماری دقت ماشینهای ترجمه را افزایش دهند و از همین رو کاربران بیشتری از ماشینهای ترجمهای نظیر Google Translate در زندگی روزمره خود بهره میگیرند برای این که بتوانیم دقت ماشینهای ترجمه و کارایی آنها را بسنجیم نیاز به روشی است علمی و عینی. یکی از راهها این است که ترجمهی ماشینی از یک یا چند متن را با ترجمه یا ترجمههای انسانی همان متن بسنجیم. به عبارت دیگر، ترجمههای خوب و روان صورت گرفته توسط مترجمان مسلط به زبان مبدأ و مقصد ملاکی برای سنجش ترجمهی ماشینی قرار میگیرد.
یکی از معتبرترین روشهای ارزیابی ترجمهی ماشینی، روش «جایگزین ارزیابی دوزبانه» یا Bleu (Bilingual Evaluation Understudy) است. پس از گردآوری دادگان موازی که متنهای زبان مبدأ و ترجمهی انسانی آنها را دربرمیگیرند، با استفاده از این روش میتوان به صورت کاملاً خودکار و با کامپیوتر در زمان کوتاهی به یک ارزیابی عینی و آماری از دقت یک ماشین ترجمه دست یافت. بدین منظور n-گرامهای برگردان ماشینی و برگردان یا برگردانهای انسانی مقایسه میگردند و موارد مشترک بین آنها شمرده میشوند. منظور از n-گرام ترکیبهای متوالی n-تایی واژگان موجود در یک متن است. «دقت» (Precision) در روش «جایگزین ارزیابی دوزبانه» به صورت زیر محاسبه میگردد:
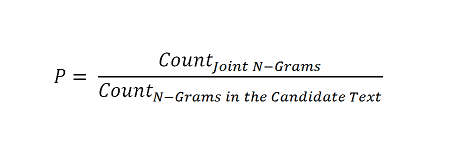
به عبارت دیگر، «دقت» تعداد n-گرامهای مشترک بین برگردان ماشینی و برگردان یا برگردانهای انسانی تقسیم بر تعداد n-گرامهای موجود در برگردان ماشینی است. بنابراین «دقت» عددی بین صفر و یک است که میتوان آن را به صورت درصد نیز بیان کرد. در مقایسهی 1-گرامی (مقایسه واژگان مشترک ترجمه ماشینی و ترجمه یا ترجمههای انسانی) کارایی ماشین ترجمه در واژهگزینی و یافتن معادل درست واژگان در زبان مقصد سنجیده میشود. در مقایسه 2-گرامی (مقایسه جفتواژگان مشترک) و در مقایسههای چند-گرامی درستی ترجمه از لحاظ نحوی نیز سنجیده میشود.
فرض کنید میخواهیم دقت ترجمهی ماشینی را برای برگردان فارسی جملهی انگلیسی زیر بدانیم:
The man in black who is reading a newspaper has bought a beautiful big house.
ترجمه ماشینی 1: مرد در سیاه که است خواندن یک روزنامه دارد خرید یک زیبا بزرگ خانه.
ترجمه ماشینی 2: مرد در سیاه که میخواند یک روزنامه خریده است یک زیبا خانه بزرگ.
ترجمه ماشینی 3: مرد در سیاه که یک روزنامه میخواند یک خانه بزرگ زیبا خریده است.
ترجمه انسانی: مرد سیاهپوش که دارد روزنامه میخواند یک خانه بزرگ و زیبا خریده است.
|
1-گرامها |
فراوانی |
|||
|
ترجمه ماشینی 1 |
ترجمه ماشینی 2 |
ترجمه ماشینی 3 |
ترجمه انسانی |
|
|
مرد |
1 |
1 |
1 |
1 |
|
در |
1 |
1 |
1 |
0 |
|
سیاه |
1 |
1 |
1 |
0 |
|
که |
1 |
1 |
1 |
1 |
|
است |
1 |
1 |
1 |
1 |
|
خواندن |
1 |
0 |
0 |
0 |
|
یک |
2 |
2 |
2 |
1 |
|
روزنامه |
1 |
1 |
1 |
1 |
|
دارد |
1 |
0 |
0 |
1 |
|
خرید |
1 |
0 |
0 |
0 |
|
زیبا |
1 |
1 |
1 |
1 |
|
بزرگ |
1 |
1 |
1 |
1 |
|
خانه |
1 |
1 |
1 |
1 |
|
میخواند |
0 |
1 |
1 |
1 |
|
خریده |
0 |
1 |
1 |
1 |
|
سیاهپوش |
0 |
0 |
0 |
1 |
|
و |
0 |
|
0 |
1 |
|
تعداد کل 1-گرامها |
14 |
13 |
13 |
13 |
همانگونه که جدول بالا نشان میدهد ترجمه ماشینی 1 دارای 9 مورد 1-گرام مشترک با ترجمهی انسانی معیار است. ترجمههای ماشینی 2 و 3 هر کدام دارای 10 مورد 1-گرام مشترک با ترجمهی انسانی معیار است. اگر تعداد این 1-گرامهای مشترک را بر تعداد کل 1-گرامهای موجود در هر کدام از ترجمههای ماشینی تقسیم کنیم، دقت ترجمه بر اساس روش «جایگزین ارزیابی دوزبانه» به دست میآید. بنابراین دقت ترجمهی ماشینی 1 حدود 64 درصد و دقت ترجمهی ماشینی 2 و 3 حدود 77 درصد است. یک ارزیابی شهودی هم نشان میدهد با وجود این که هر سه ترجمهی ماشینی ضعیف هستند اما ترجمههای دوم و سوم تا حدودی واضحتر هستند. ترجمهی ماشینی اول در برگردان فعلهای جمله به زبان مقصد کاملاً ناموفق بوده است، اما ترجمههای ماشینی دوم و سوم فعلها را درست ترجمه کردهاند. با وجود این، روابط نحوی در شمارش 1-گرامهای مشترک نادیده گرفته میشود و نیاز به شمارش 2-گرامها یا چند-گرامهای مشترک است. همان گونه که آشکار است هر چند که ترجمهی ماشینی 3 از ترجمهی ماشینی 2 روانتر است، اما هر دو دقت یکسانی را کسب کردهاند.
|
2-گرامها |
فراوانی |
|||
|
ترجمه ماشینی 1 |
ترجمه ماشینی 2 |
ترجمه ماشینی 3 |
ترجمه انسانی |
|
|
* مرد |
1 |
1 |
1 |
1 |
|
مرد در |
1 |
1 |
1 |
0 |
|
در سیاه |
1 |
1 |
1 |
0 |
|
سیاه که |
1 |
1 |
1 |
0 |
|
که است |
1 |
0 |
0 |
0 |
|
است خواندن |
1 |
0 |
0 |
0 |
|
خواندن یک |
1 |
0 |
0 |
0 |
|
یک روزنامه |
1 |
1 |
1 |
0 |
|
روزنامه دارد |
1 |
0 |
0 |
0 |
|
دارد خرید |
1 |
0 |
0 |
0 |
|
خرید یک |
1 |
0 |
0 |
0 |
|
یک زیبا |
1 |
1 |
0 |
0 |
|
زیبا بزرگ |
1 |
0 |
0 |
0 |
|
بزرگ خانه |
1 |
0 |
0 |
0 |
|
خانه * |
1 |
0 |
0 |
0 |
|
که میخواند |
0 |
1 |
0 |
0 |
|
میخواند یک |
0 |
1 |
1 |
1 |
|
روزنامه خریده |
0 |
1 |
0 |
0 |
|
خریده است |
0 |
1 |
1 |
1 |
|
است یک |
0 |
1 |
0 |
0 |
|
زیبا خانه |
0 |
1 |
0 |
0 |
|
خانه بزرگ |
0 |
1 |
1 |
1 |
|
بزرگ * |
0 |
1 |
0 |
0 |
|
مرد سیاهپوش |
0 |
0 |
0 |
1 |
|
سیاهپوش که |
0 |
0 |
0 |
1 |
|
که دارد |
0 |
0 |
0 |
1 |
|
دارد روزنامه |
0 |
0 |
0 |
1 |
|
روزنامه میخواند |
0 |
0 |
1 |
1 |
|
یک خانه |
0 |
0 |
1 |
1 |
|
بزرگ و |
0 |
0 |
0 |
1 |
|
و زیبا |
0 |
0 |
0 |
1 |
|
زیبا خریده |
0 |
0 |
1 |
1 |
|
است * |
0 |
0 |
1 |
1 |
|
که یک |
0 |
0 |
1 |
0 |
|
بزرگ زیبا |
0 |
0 |
1 |
0 |
|
تعداد کل 2-گرامها |
15 |
14 |
14 |
14 |
همانگونه که در بالا میبینید ترجمه ماشینی 1 دارای تنها 1 مورد 2-گرام مشترک با ترجمهی انسانی معیار است. ترجمهی ماشینی 2 و 3 به ترتیب دارای 3 و 8 مورد 2-گرام مشترک با ترجمهی انسانی معیار هستند. اگر تعداد این 2-گرامهای مشترک را بر تعداد کل 2-گرامهای موجود در هر کدام از ترجمههای ماشینی تقسیم کنیم، دقت ترجمه بر اساس روش «جایگزین ارزیابی دوزبانه» به دست میآید. بنابراین دقت ترجمهی ماشینی 1 حدود 6.7 درصد، دقت ترجمهی ماشینی 2 حدود 21.4 درصد و دقت ترجمهی ماشینی 3 حدود 57 درصد است. این بدان معناست با وجود این که ترجمههای ماشینی 2 و 3 از لحاظ واژهگزینی یکساناند اما از لحاظ چیدمان نحوی، ترجمهی ماشینی 3 به ترجمهی انسانی معیار نزدیکتر است. یک ارزیابی شهودی نیز نشان میدهد که بیشک ترجمه ماشینی سوم از ترجمهی دوم و به مراتب از ترجمهی اول روانتر است.
بدیهی است اگر بخواهیم یک ترجمهی انجام شده توسط ماشین را با چند ترجمهی انسانی بسنجیم، میانگین دقتهای به دست آمده را به مثابهی دقت ترجمهی ماشینی در نظر میگیریم.
روش «جایگزین ارزیابی دوزبانه» موجب صرفهجویی بسیار در مدت زمان ارزیابی یک ماشین ترجمه میشود بهویژه اگر بخواهیم یک سامانه را با انبوهی از دادگان موازی بسنجیم. از سوی دیگر، این نوع ارزیابی عینی، ملموس و مبتنی بر یک مقیاس عددی است و ما را از شر تحلیلهای صرفاً شهودی و شمی خلاص میکند. با وجود این، باید مراقب بود دادگانی که برای سنجش ماشین ترجمه به کار میروند برای آموزش سامانه به کار برده نشده باشند تا در ارزیابی خود دچار سوگیری نشویم.
منابع:
· Calculate BLEU score (Bilingual Evaluation Understudy) from Papineni, Kishore, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. "BLEU: a method for automatic evaluation of machine translation." In Proceedings of ACL. http://www.aclweb.org/anthology/P02-1040.pdf
· Papineni, K.; Roukos, S.; Ward, T.; Zhu, W. J. (2002). BLEU: a method for automatic evaluation of machine translation (PDF). ACL-2002: 40th Annual meeting of the Association for Computational Linguistics. pp. 311–318.